Paper Summary: Large Language Models Encode Clinical Knowledge
This is a recent paper (December 2022) from Google Research and DeepMind that appeared in Arxiv.
TL; DR: The paper introduces a Large Language Model (LLM) that is tailored to answer questions about clinical (medical) domain. It achieves SOTA results on various domain specific datasets.
Large Language Models continue to demonstrate great potentials in natural language understanding and generation. These models do not just answer factual questions such as: “Where is Eifel Tower?” but also show signs of reasoning and coming up with answers that mymics human thought process. Even though we are still early in the journey, there are increasing number of demonstrations of LLMs in domain specific use cases. In this paper, authors explored how LLMs can be used to answer questions in clinical domain.
Since this is a paper from Google, the authors utilize Google’s PaLM, a 540-billion parameter, dense decoder-only Transformer model trained with the Pathways system. Currently, there are various challenges, such as hallucinations, consistency, in LLMs that prevent wider adoption in critical domains such as in clinical settings. Authors recognize these challenges and introduce a framework for human evaluation of model answers. I think this is critical for these kinds of systems as we are currently not there yet to comprehensively evaluate the accuracy of these models.
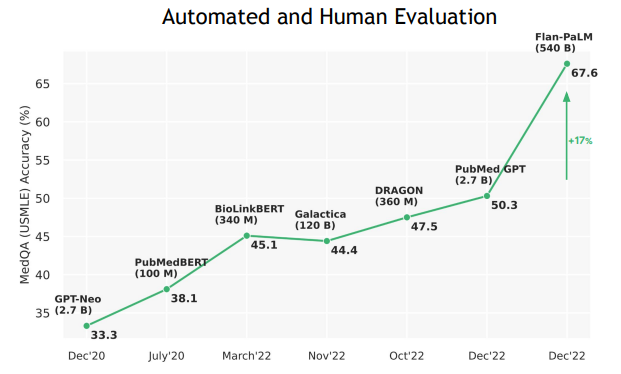
The paper showcased that Flan-PaLM (an instruction-tuned variant of PaLM itself), achieves SOTA on various benchmarks. It uses a combination of few shot, chain of thoughts and self-consistency prompting strategies. At the same time, human evaluation reveals that there are gaps in responses. To alleviate this author introduced “instruction prompt tuning”, a parameter-efficient alignment of LLMs to new domains using a few examples and called the new model Med-PaLM, which basically applied instruction prompt tuning to adapt Flan-PaLM to medical domain. Med-PaLM sampled examples from MultiMedQA free-response datasets (HealthSearchQA, MedicationQA, LiveQA). A panel of five clinicians asked to provide exemplar answers, in total 40 examples used for instruction prompt tuning training. Notice the few examples used to tune the model. The results show promising but still inferior to clinicians.

As LLMs shows promising results, clinical settings will be one area companies will definetely target, however at the same time, it will be one of the most challenging ones given the regulations and human aspects.